Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
AIBrix KVCache Offloading Framework — AIBrix
KV Cache Offload Accelerates LLM Inference - NADDOD Blog
Scaling Multi-Turn LLM Inference with KV Cache Storage Offload and Dell ...
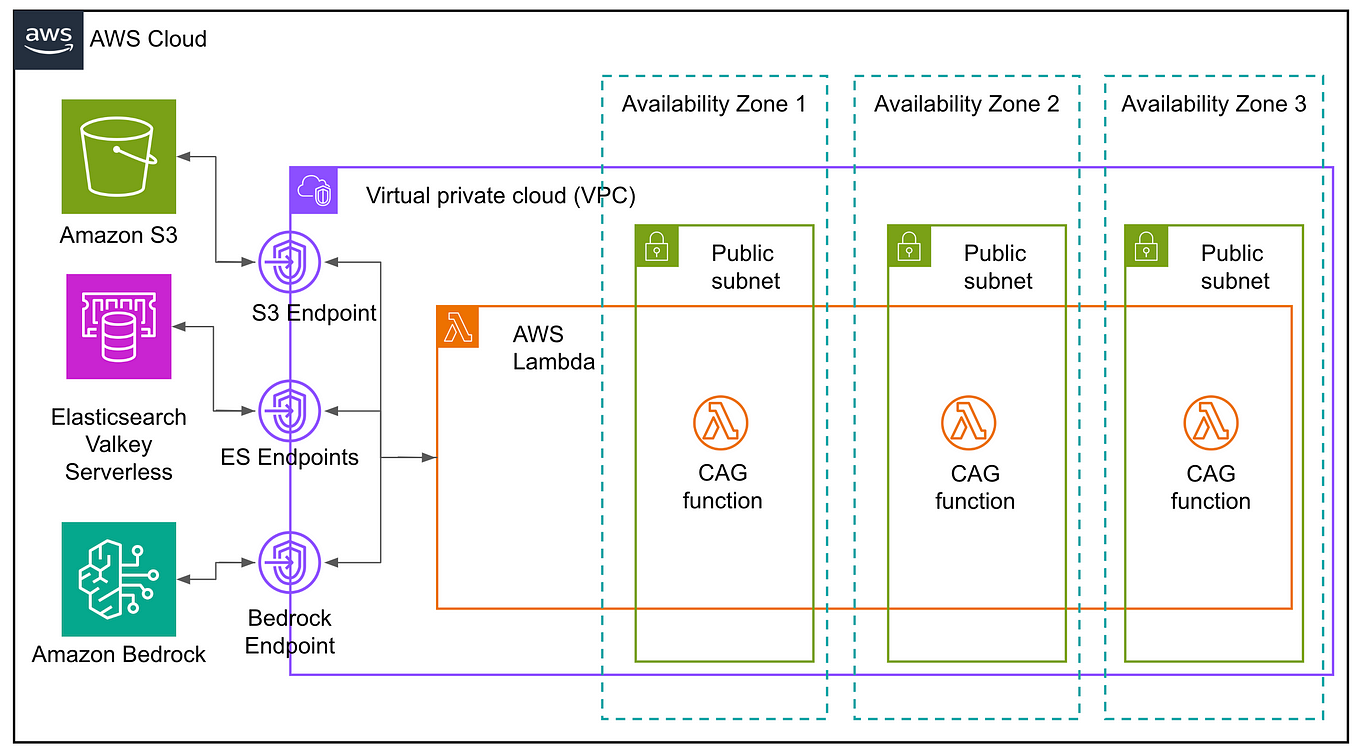
Accelerate Large-Scale LLM Inference and KV Cache Offload with CPU-GPU ...
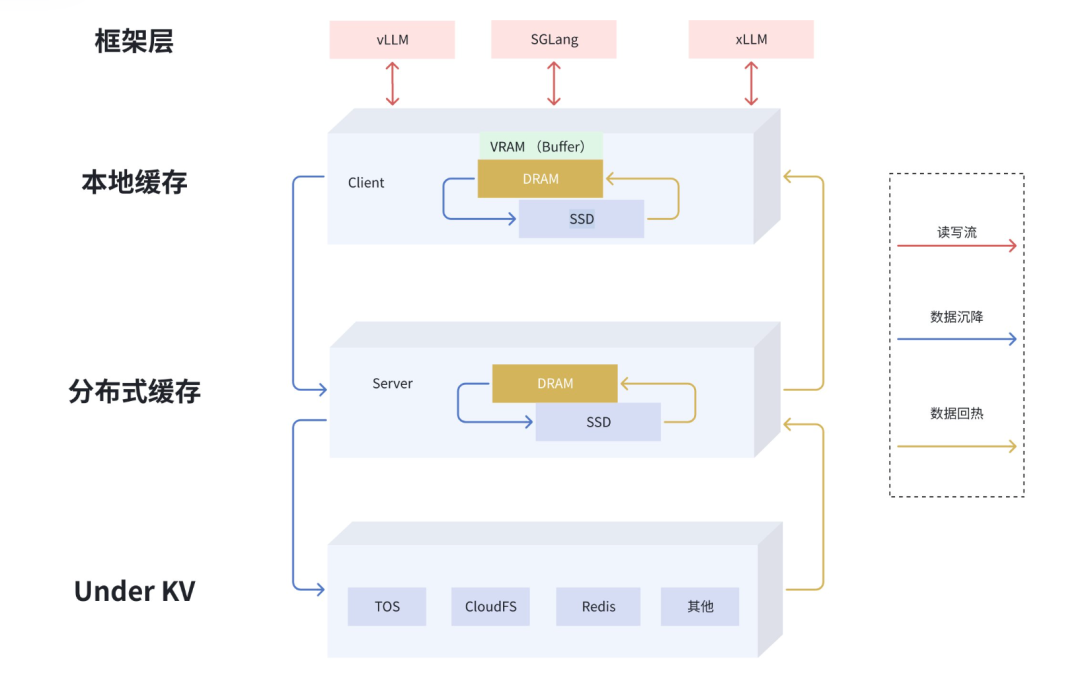
推理加速新范式:火山引擎高性能分布式 KVCache (EIC)核心技术解读_分布式kv-CSDN博客
[논문 리뷰] CLO: Efficient LLM Inference System with CPU-Light KVCache ...
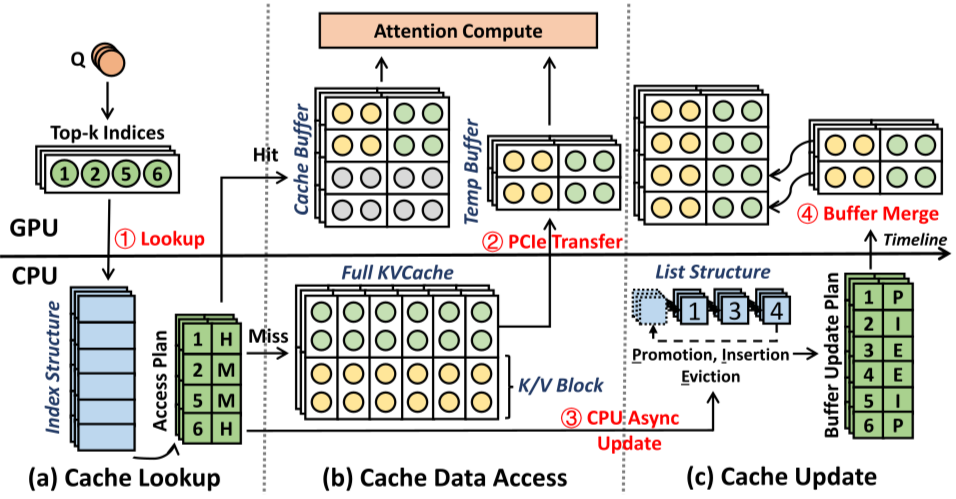
CLO: Efficient LLM Inference System with CPU-Light KVCache Offloading ...
KVstar: A KVcache Offloading Scheme for LLM decoding with High ...
KV_cache offload · Issue #943 · deepspeedai/DeepSpeedExamples · GitHub
Deep Long-term Memory for GenAI Inference – Beyond KV Cache Offload ...
LLM Inference: Accelerating Long Context Generation with KV Cache ...
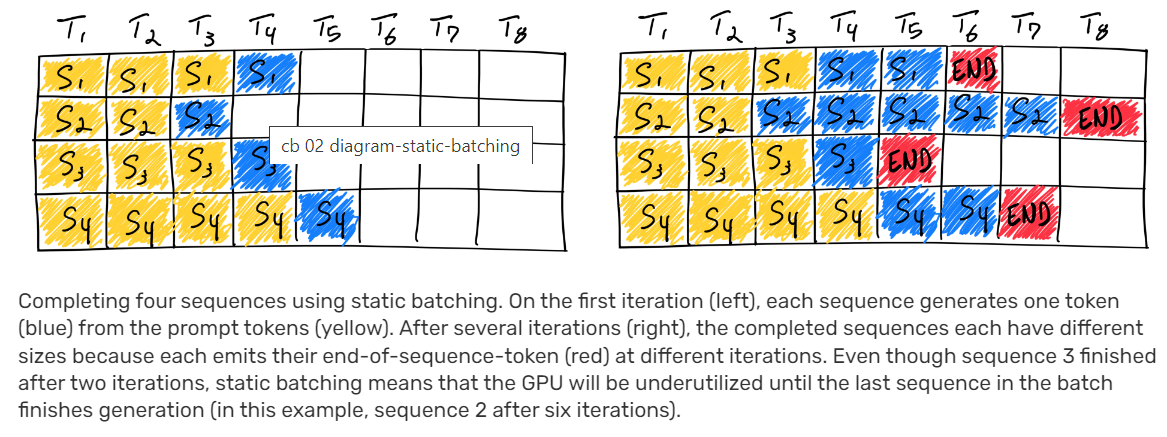
LLM Inference Optimisation — Continuous Batching | by YoHoSo | Medium
KV Cache Offloading for LLM Inference Using CXL-UEC Fabrics (Part II)
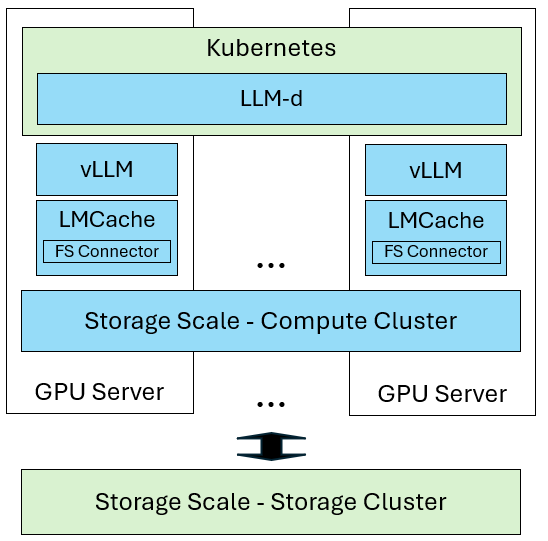
Deploying Distributed LLM Inference Service with IBM Storage Scale for ...
LLM Inference — Optimizing the KV Cache for High-Throughput, Long ...
加速LLM大模型推理,KV缓存技术详解与PyTorch实现-CSDN博客
ExtraTech Bootcamps
Mastering LLM Techniques: Inference Optimization – GIXtools
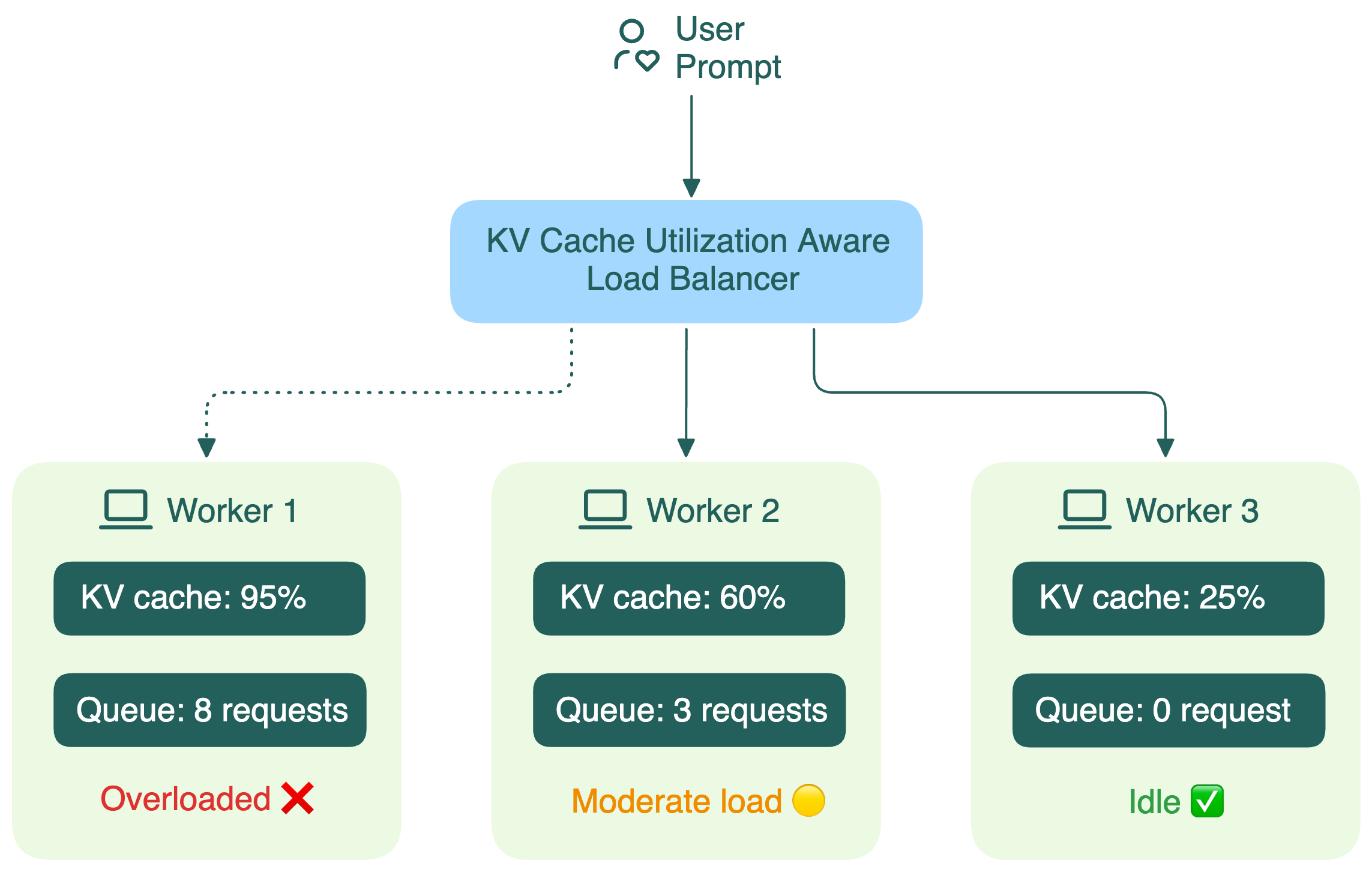
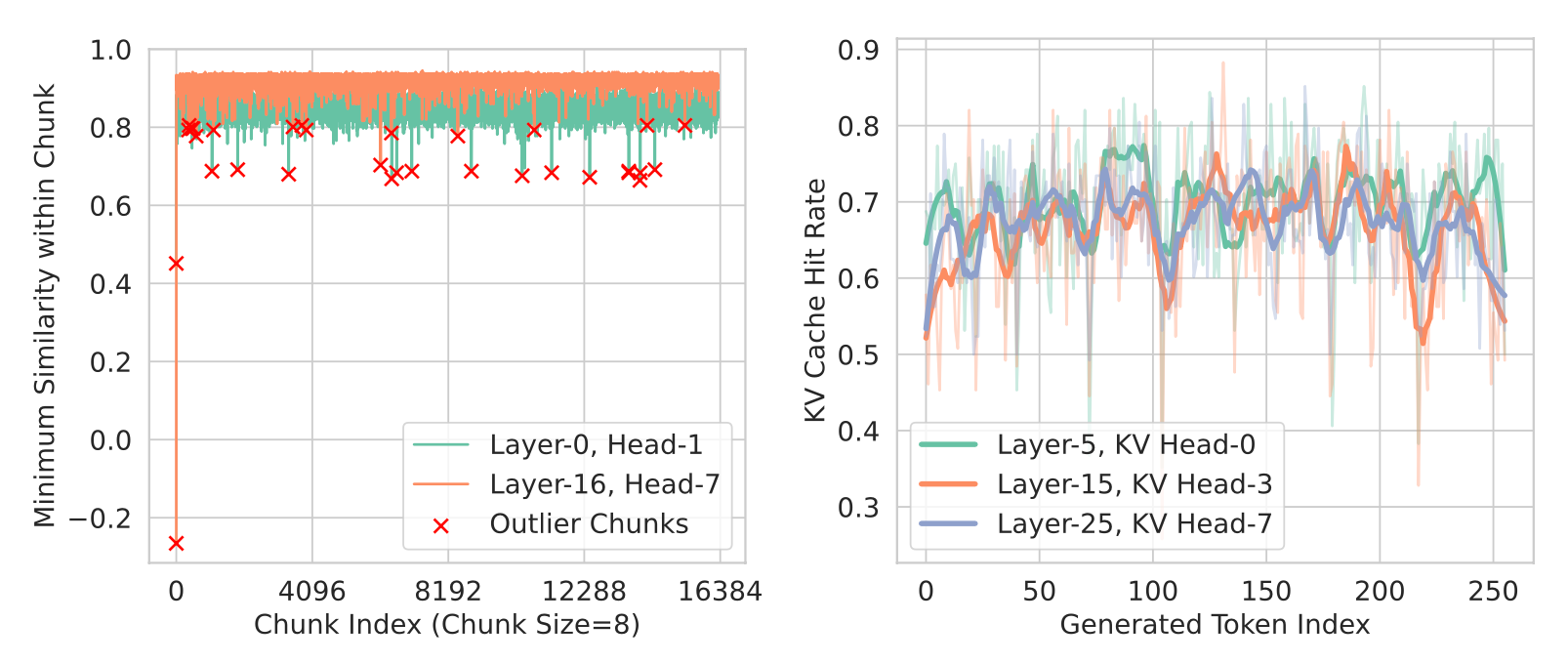
KV cache utilization-aware load balancing | LLM Inference Handbook
KV Cache量化技术详解:深入理解LLM推理性能优化_ollama kv cache-CSDN博客
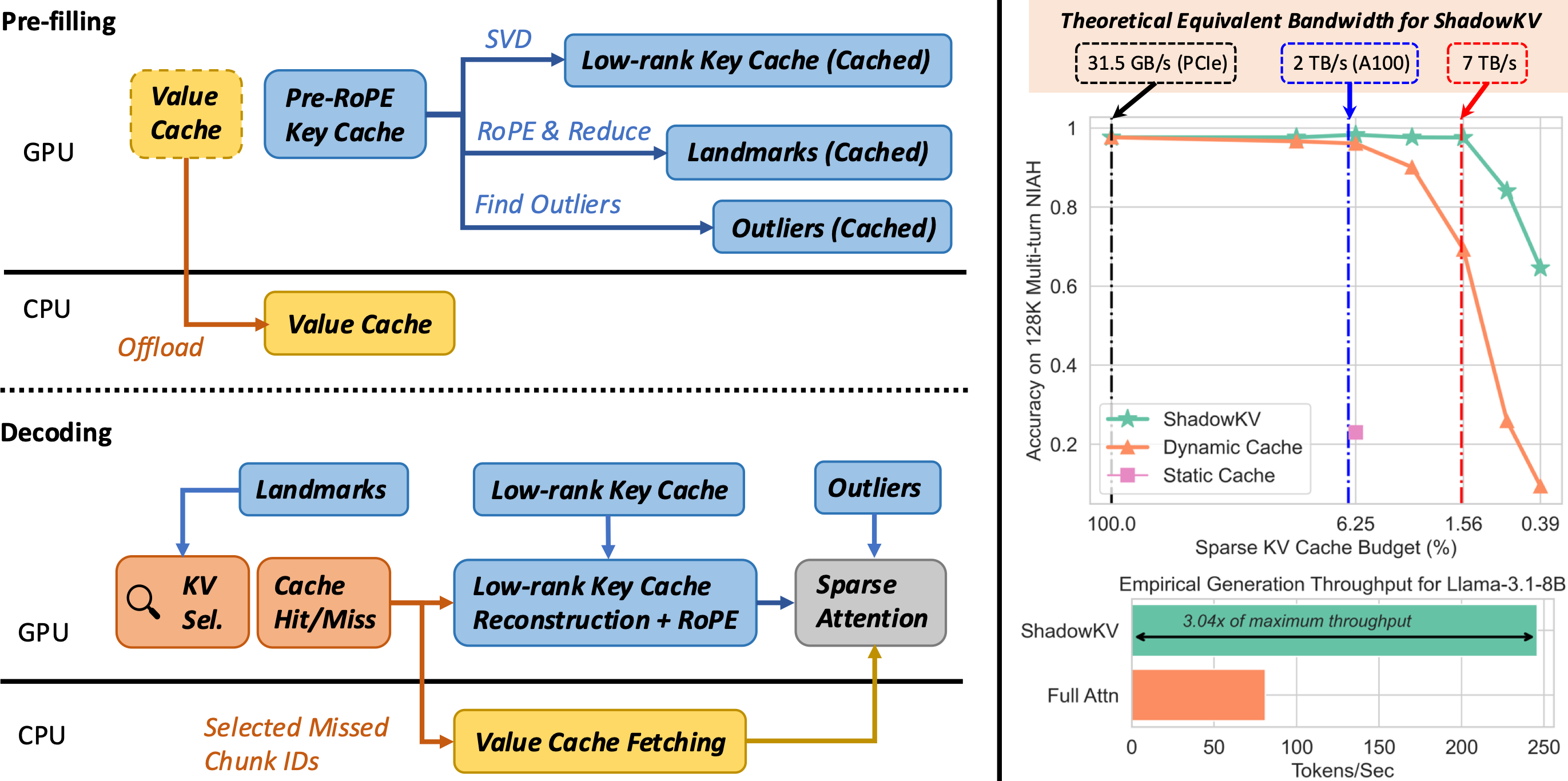
ShadowKV: KV Cache in Shadows for High-Throughput Long-Context LLM ...
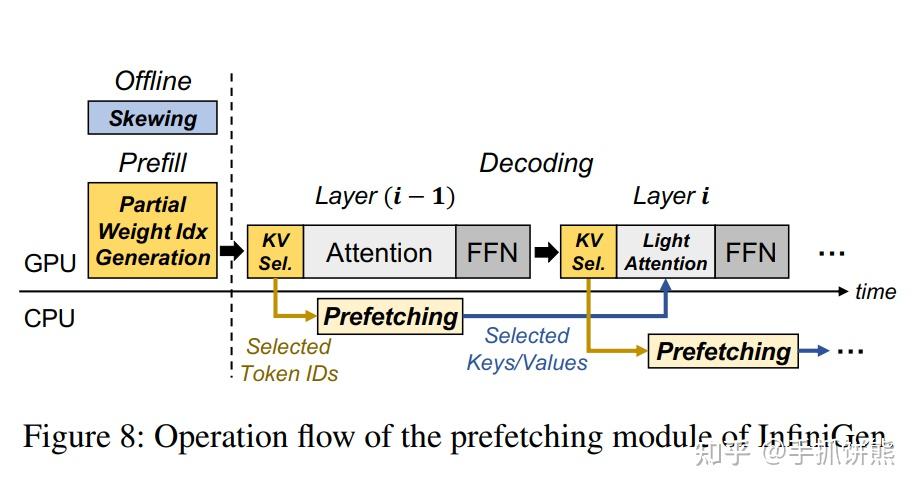
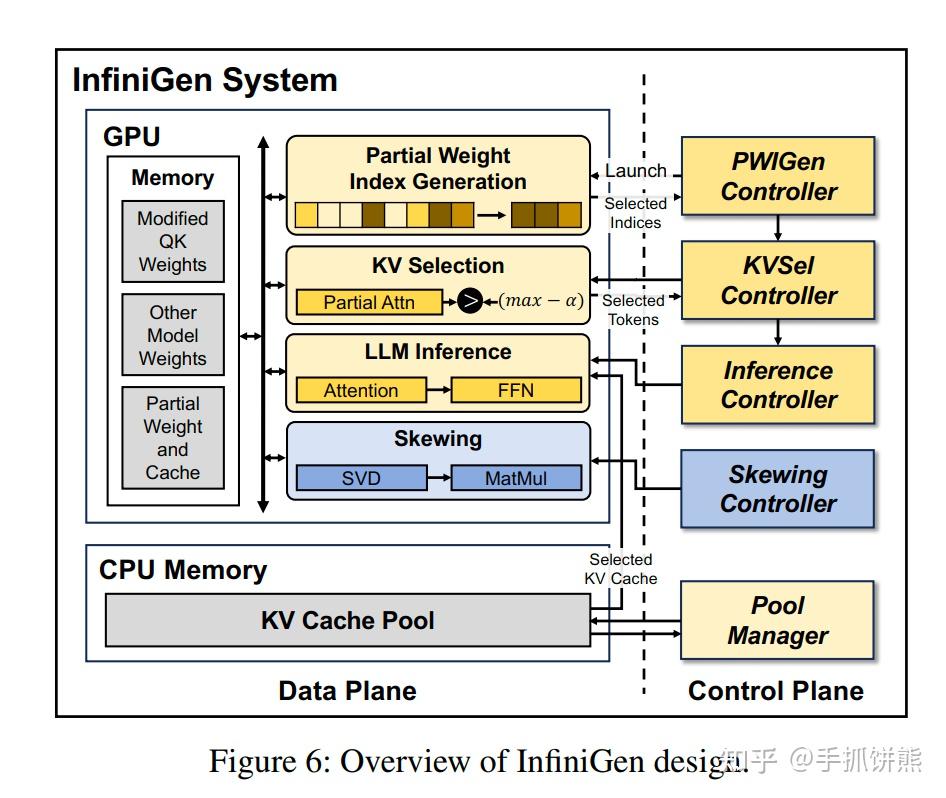
InfiniGen: Efficient Generative Inference of Large Language Models with ...
KV Caches and Time-to-First-Token: Optimizing LLM Performance
A Guide to LLM Inference (Part 1): Foundations – Stephen Carmody
LLM Inference Optimization: NADDOD Joins NVIDIA and Industry Leaders to ...
KV Cache量化技术详解:深入理解LLM推理性能优化-EW帮帮网
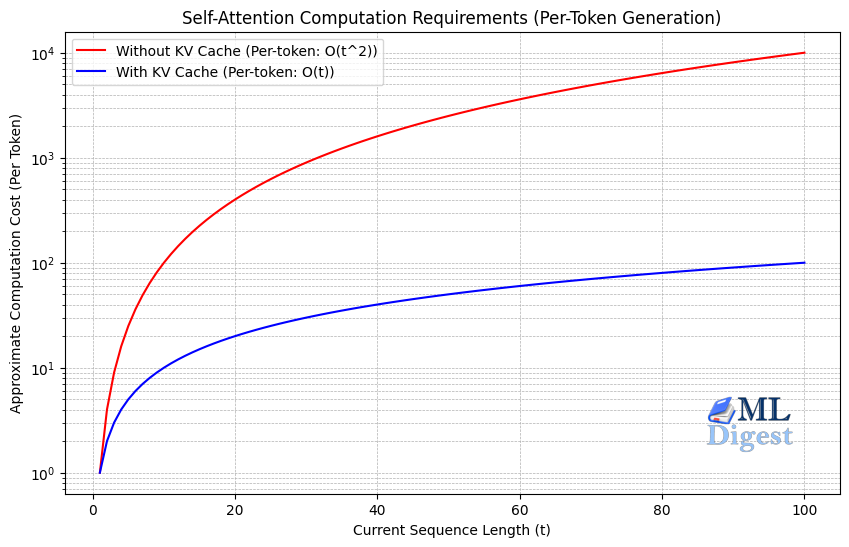
Understanding KV Caching: The Key To Efficient LLM Inference - ML Digest
KV cache offloading | LLM Inference Handbook
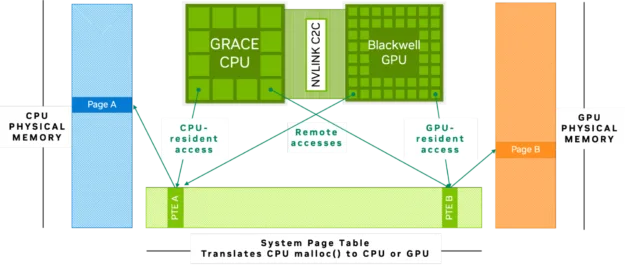
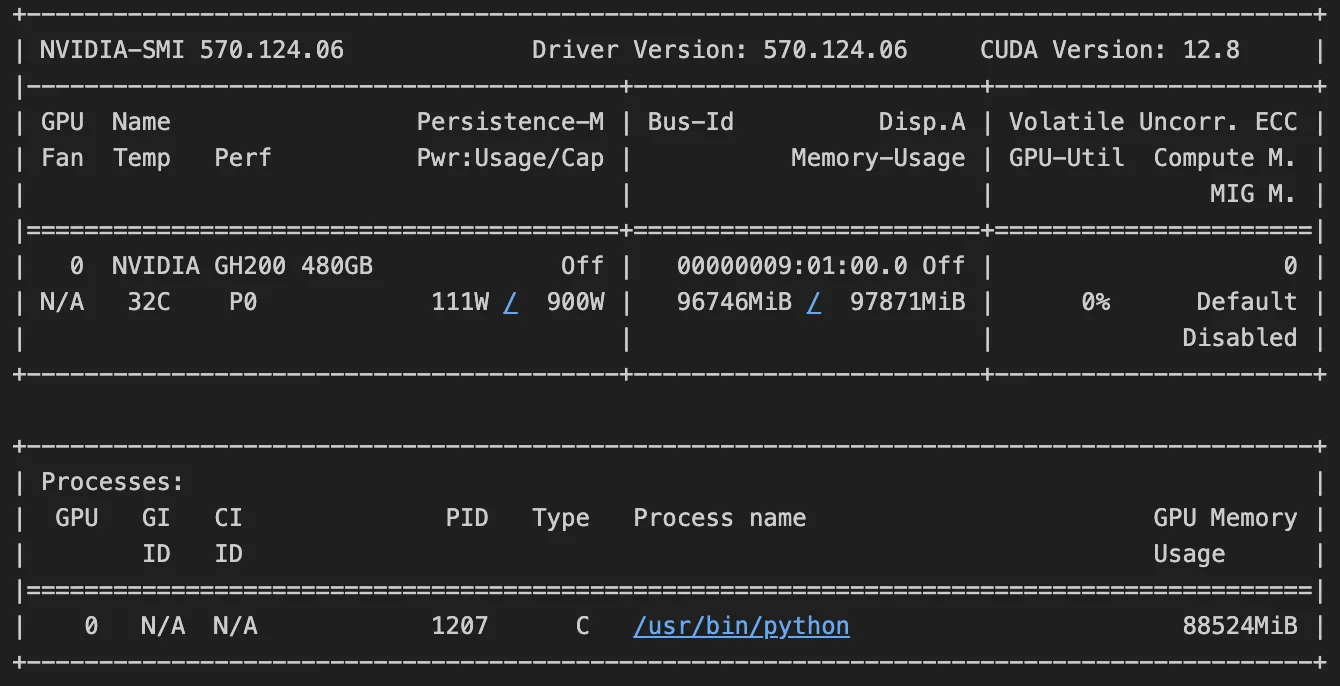
NVIDIA GH200 Superchip Accelerates Inference by 2x in Multiturn ...
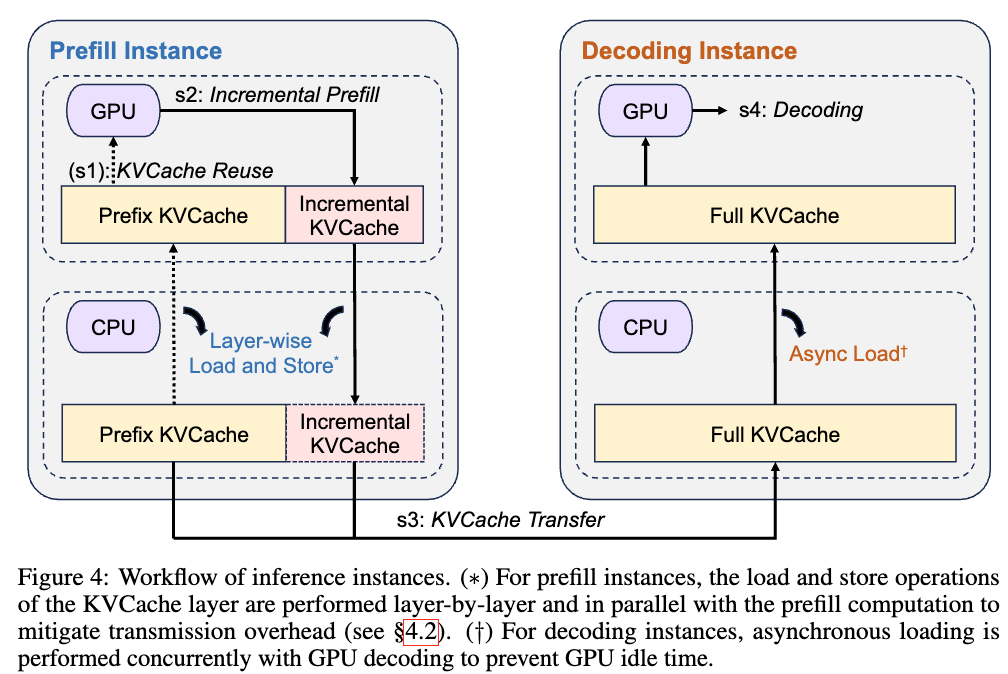
[论文笔记]Mooncake: A KVCache-centric Disaggregated Architecture for LLM ...
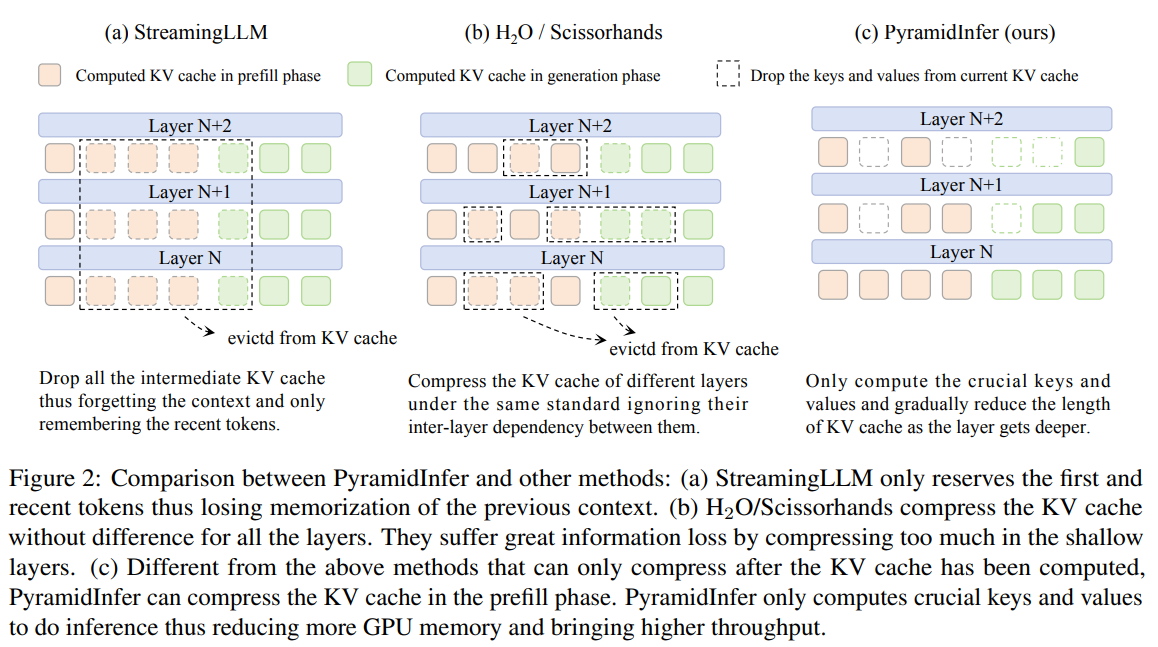
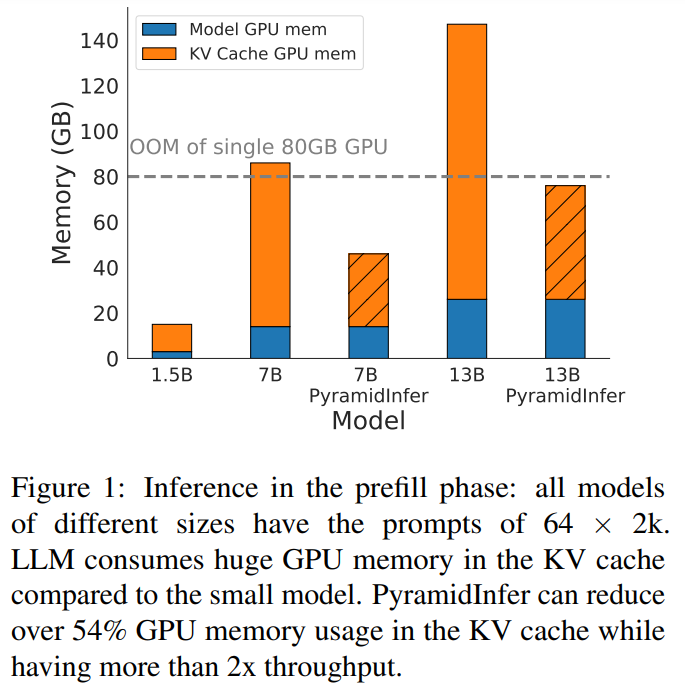
PyramidInfer: Allowing Efficient KV Cache Compression for Scalable LLM ...
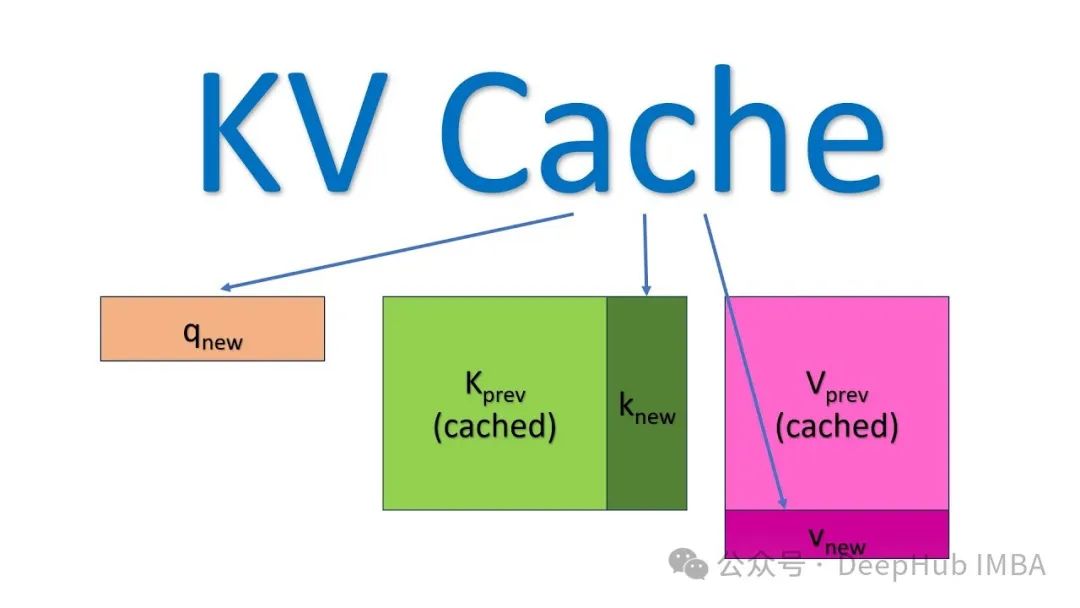
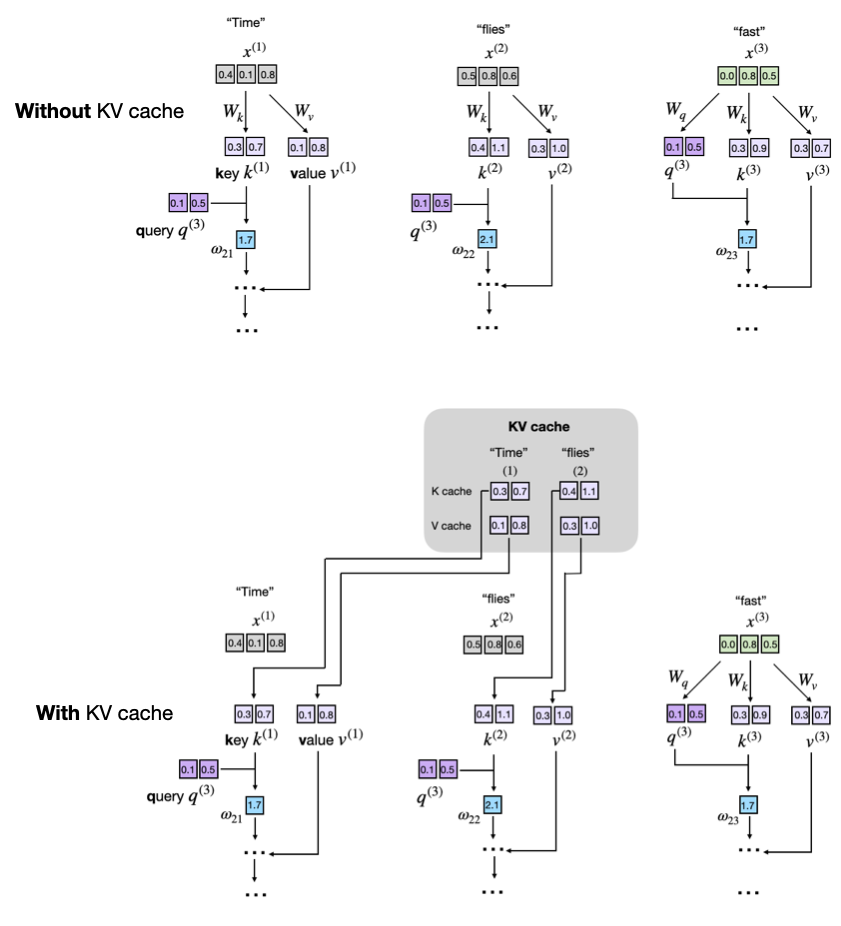
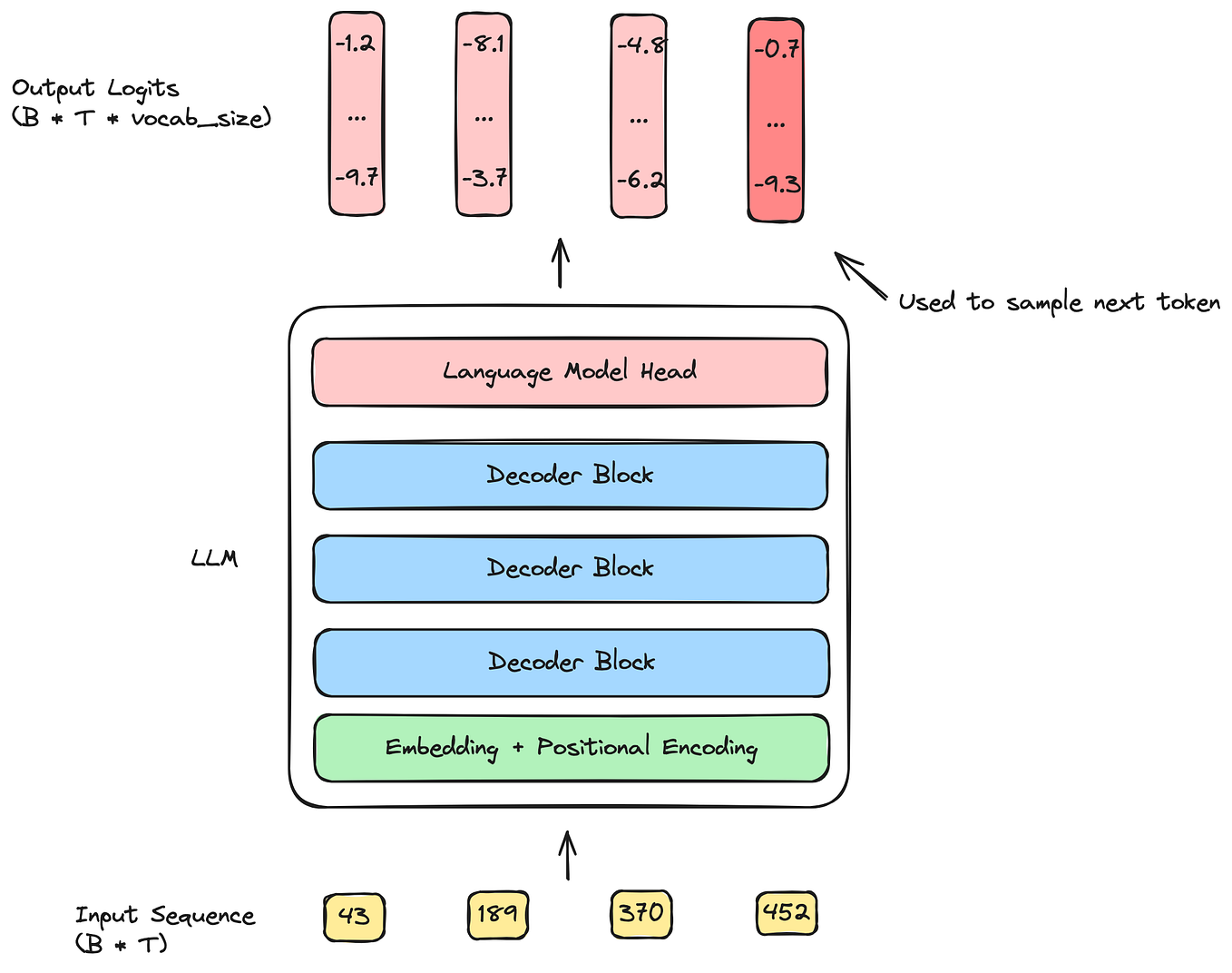
【大模型LLM基础】自回归推理生成的原理以及什么是KV Cache?_kv cache示意图-CSDN博客
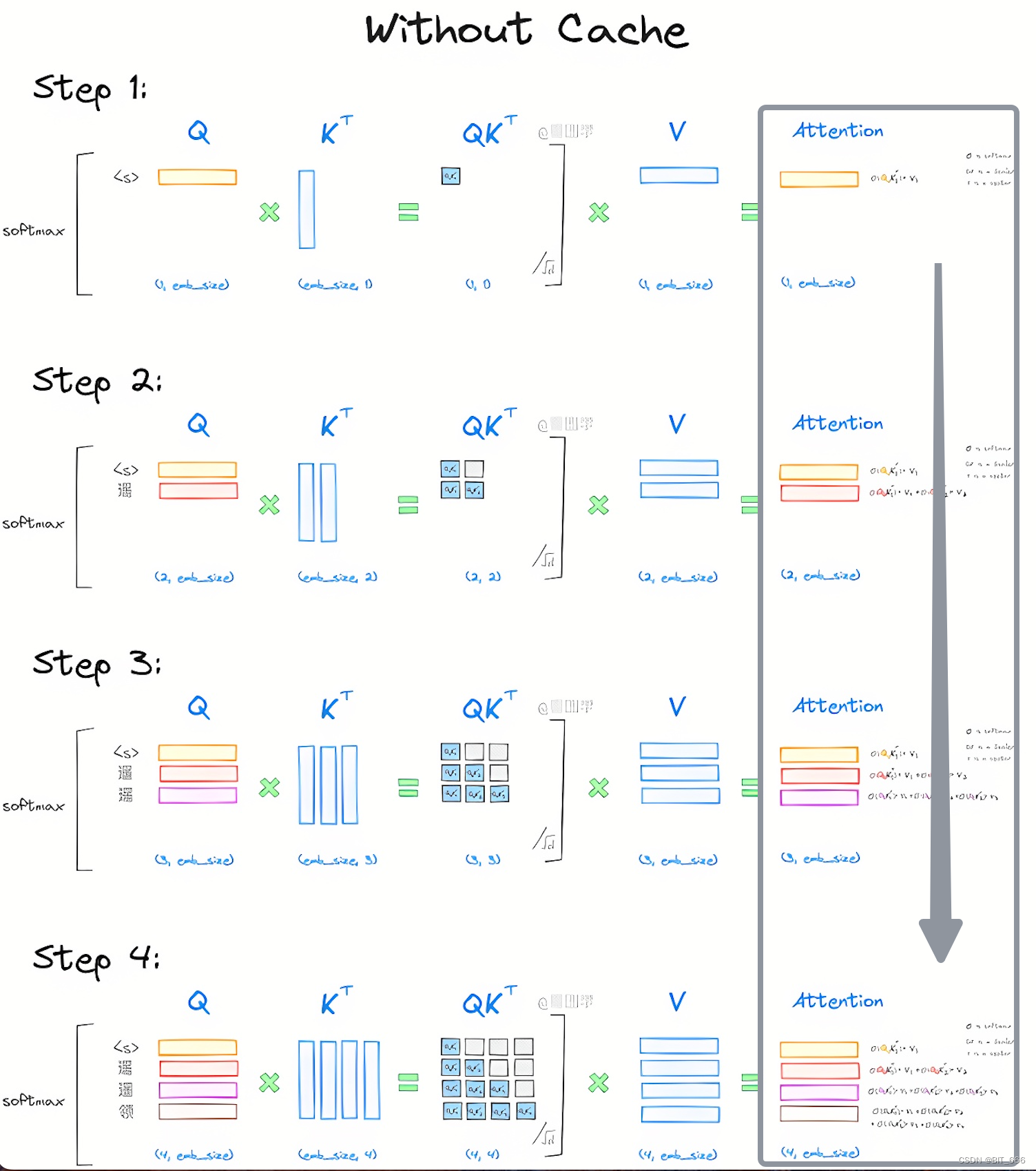
LLM - Generate With KV-Cache 图解与实践 By GPT-2_llm kv cache-CSDN博客
Optimizing Inference for Long Context and Large Batch Sizes with NVFP4 ...
Understanding KV Cache and Paged Attention in LLMs: A Deep Dive into ...
LLM - Generate With KV-Cache 图解与实践 By GPT-2_gpt2 kv缓存的使用和实现-CSDN博客
Optimizing LLM Inference: Managing the KV Cache | by Aalok Patwa | Medium
KV Cache量化技术详解:深入理解LLM推理性能优化 - 知乎
KV cache 缓存与量化:加速大型语言模型推理的关键技术 - 知乎
图文详解LLM inference:KV Cache - 知乎
Understanding and Coding the KV Cache in LLMs from Scratch
The Shift to Distributed LLM Inference: 3 Key Technologies Breaking ...
[Literature Review] KV Cache Transform Coding for Compact Storage in ...
Implementing KV-Caching from Scratch | Detailed LLM Inference ...
How to Reduce KV Cache Bottlenecks with NVIDIA Dynamo | NVIDIA ...
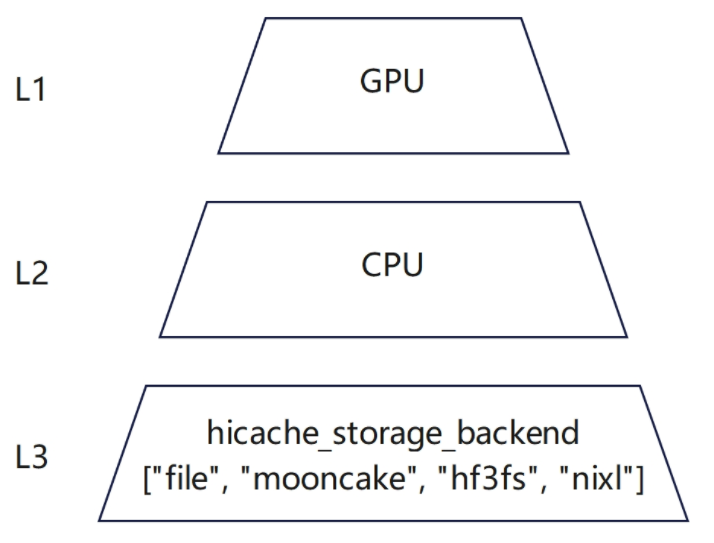
SGLang HiCache KV Cache offload-CSDN博客
20. Inference Acceleration (WIP) — LLM Foundations
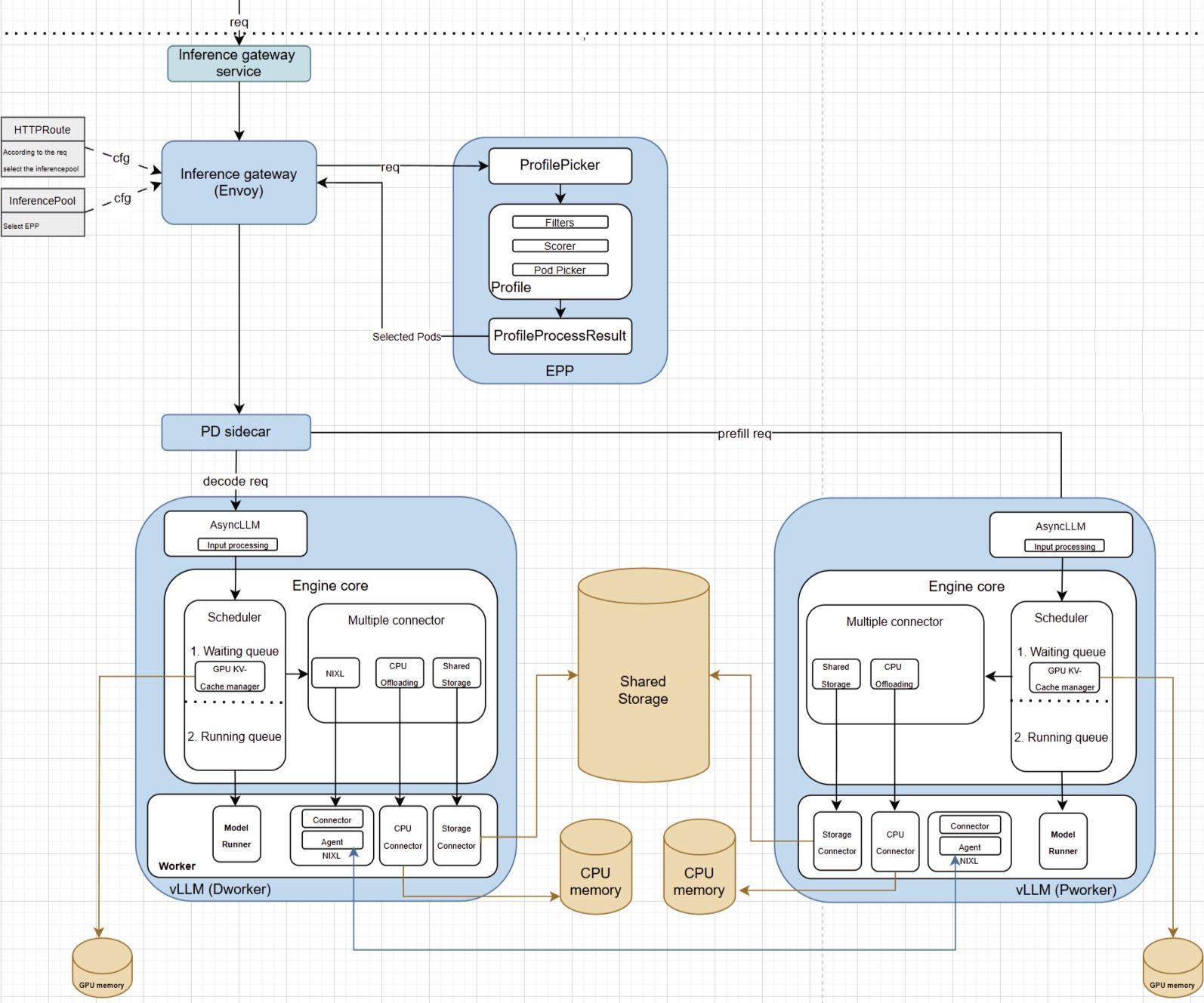
Distributed Inference Serving - vLLM, LMCache, NIXL and llm-d - Speaker ...
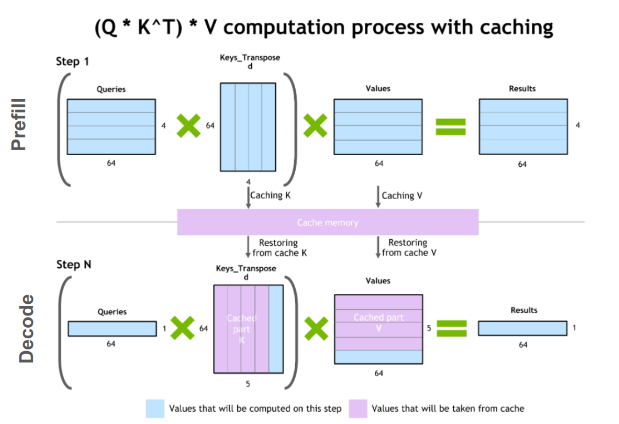
LLM Inference Series: 3. KV caching explained | by Pierre Lienhart | Medium
KV Caching in LLMs, Explained Visually. - by Avi Chawla
NVIDIA Dynamo, A Low-Latency Distributed Inference Framework for ...
LLM inference optimization - KV Cache - MartinLwx's Blog
How KV Cache Works & Why It Eats Memory | by M | Foundation Models Deep ...
KV Cache Offloading to NVMe: Progress and Questions
LLM推理性能优化:KV Cache技术演进解析 - 开发技术 - 冷月清谈
LLM Inference Series: 4. KV caching, a deeper look | by Pierre Lienhart ...
KV-Cache Offload: Keep Tokens Flying on Modest GPUs | by Bhagya Rana ...
Mastering LLM Techniques: Inference Optimization | NVIDIA Technical Blog
大模型推理优化实践:KV cache 复用与投机采样_kvcache-CSDN博客
LLM高效推理:KV缓存与分页注意力机制深度解析-51CTO.COM
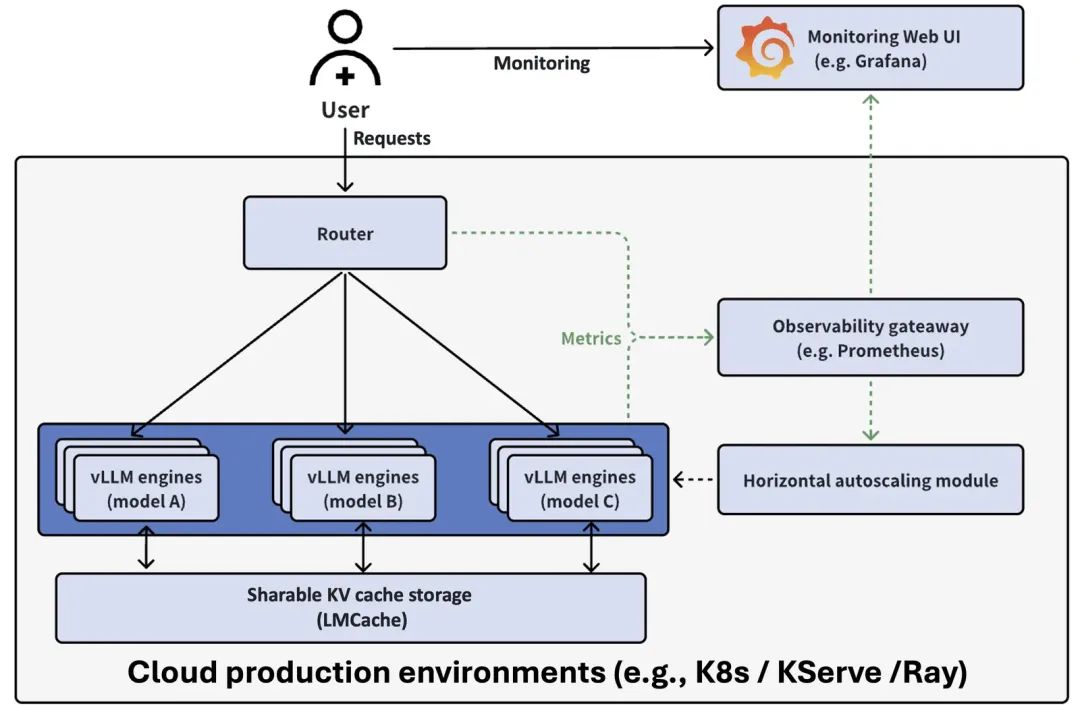
Master KV cache aware routing with llm-d for efficient AI inference ...
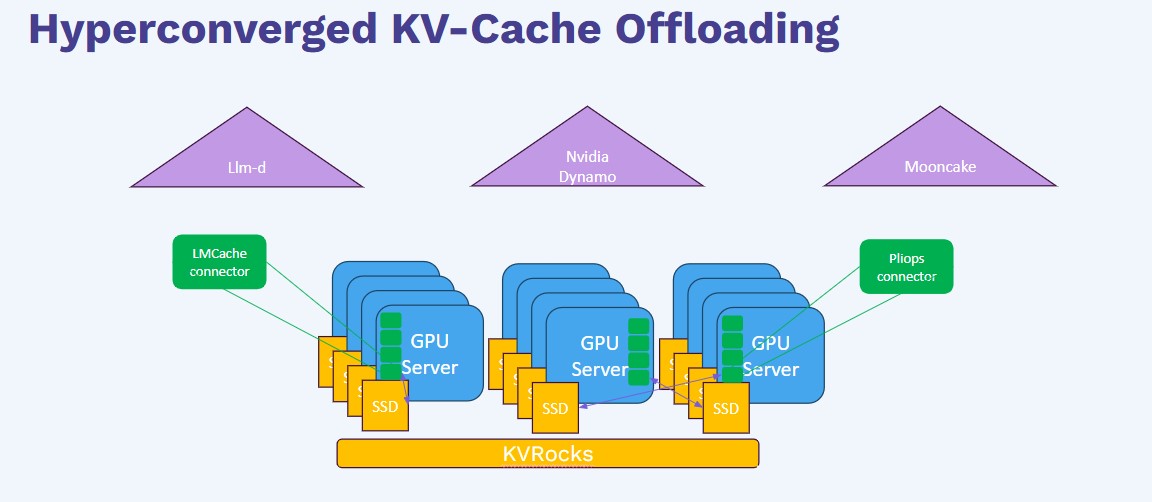
How Pliops LightningAI Redefines KV-Cache Offloading for Scalable GenAI ...
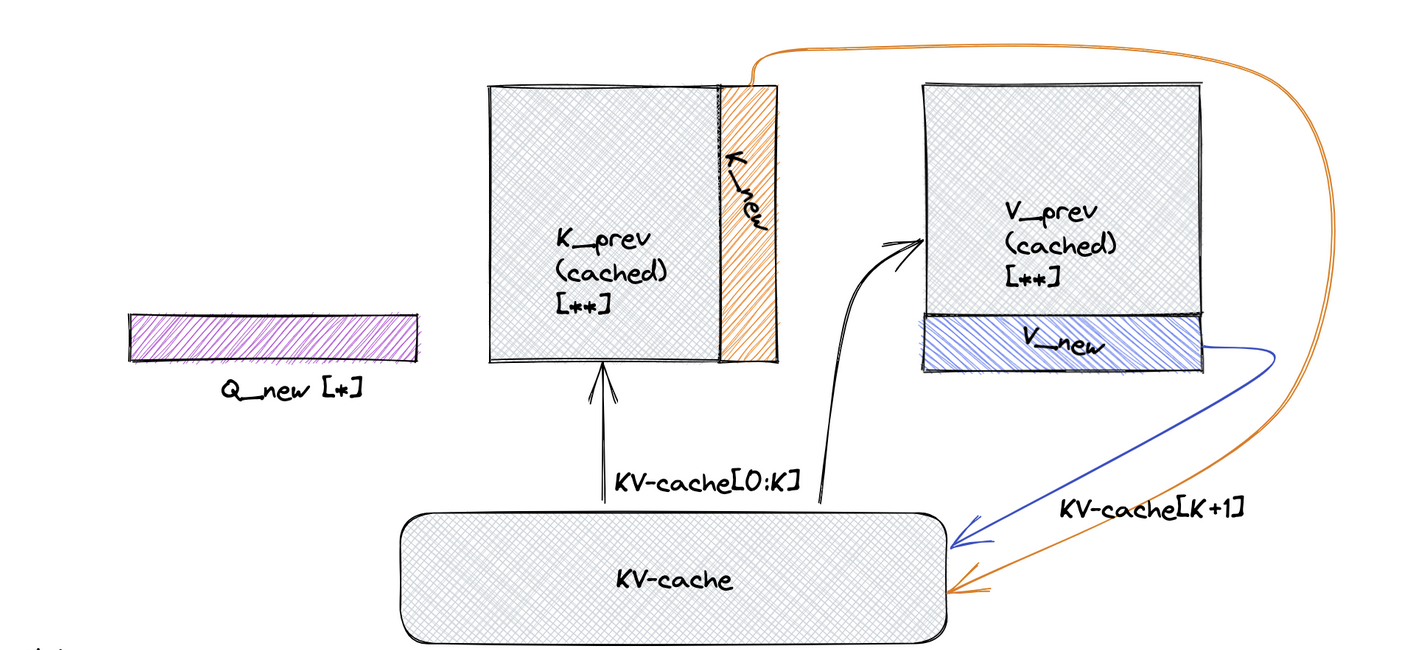
KV Cache is a very important technique to improve LLM inference latency ...
LLM Inference - KV Cache Offloading to ONTAP with vLLM and GDS - NetApp ...
LLM KV Cache Offloading: Analysis and Practical Considerations by ...
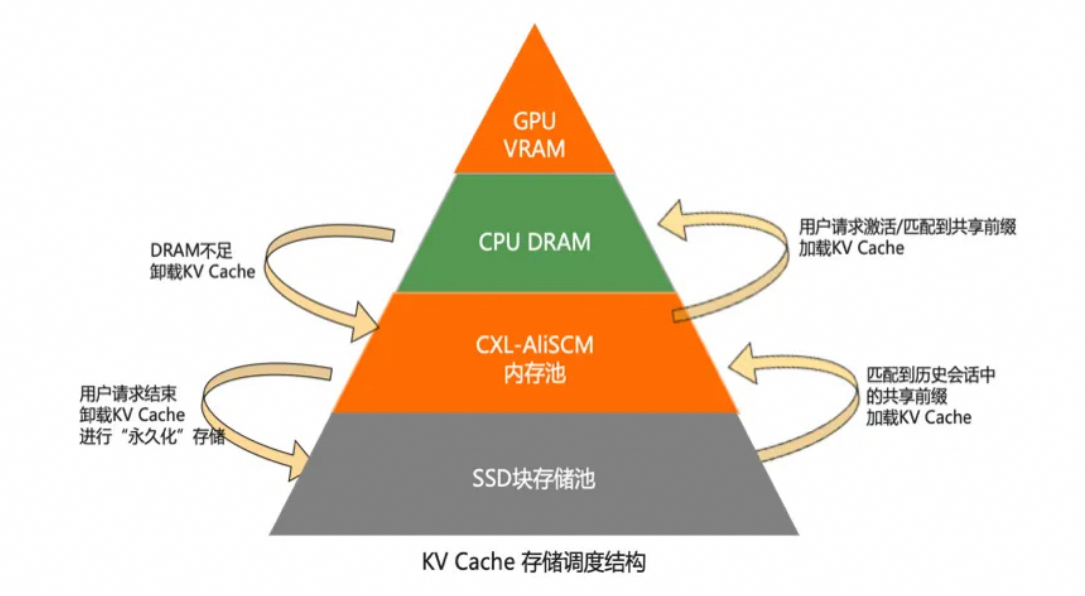
阿里云Tair KVCache:打造以缓存为中心的大模型Token超级工厂-阿里云开发者社区
Reduce LLM Latency : KV Caching. How to serve LLMs ? | by Anuva Sharma ...
Pliops Announces Collaboration with vLLM Production Stack to Enhance ...
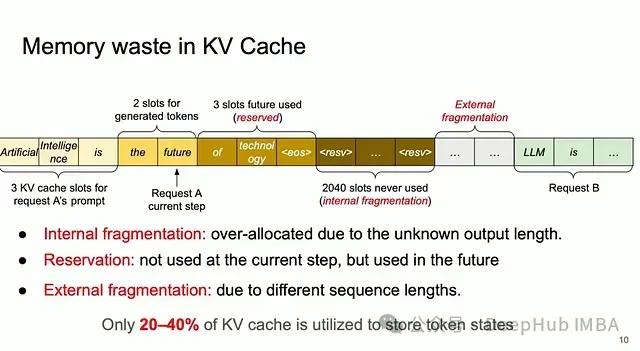
探秘Transformer系列之(24)--- KV Cache优化 - 罗西的思考 - 博客园
GenAI LLM KV Cache Offloading - Pliops CTO Lecture | Pliops LightningAI
Memory Optimization in LLMs: Leveraging KV Cache Quantization for ...
Meet 'kvcached': A Machine Learning Library to Enable Virtualized ...
Transformers KV Caching Explained | by João Lages | Medium
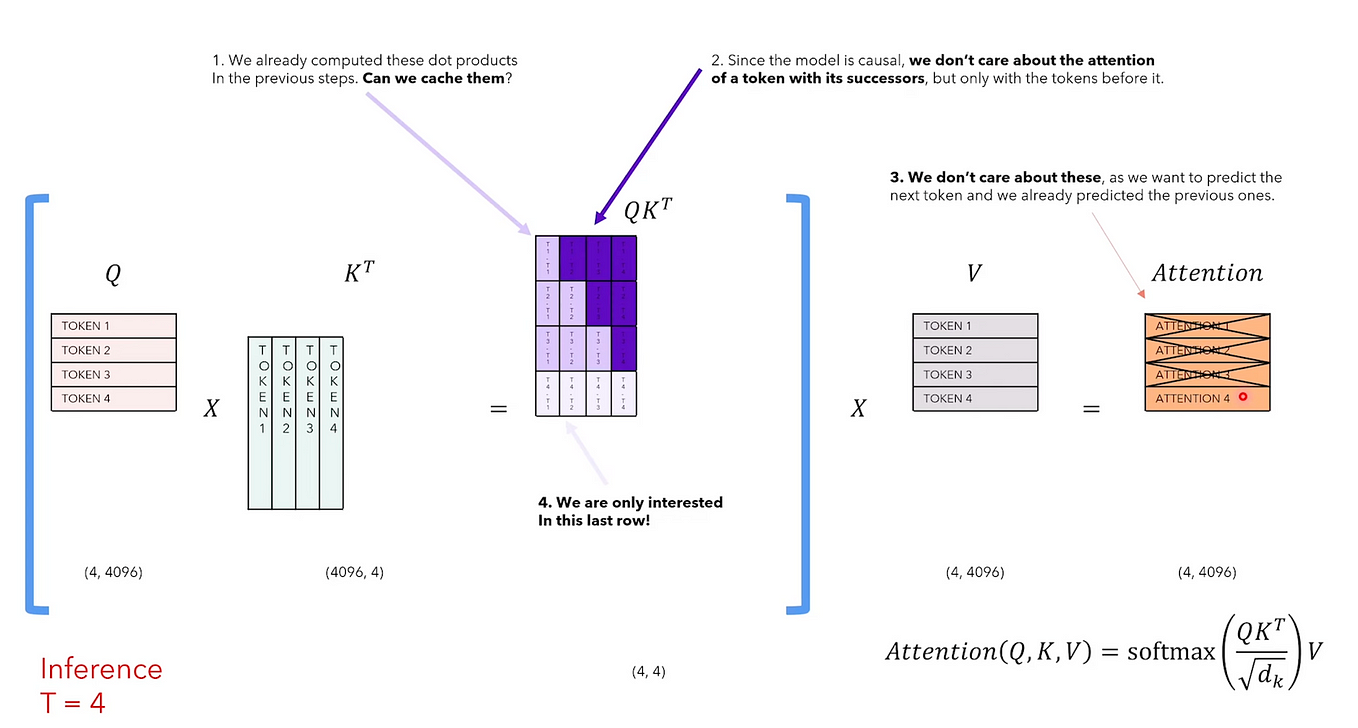
LLM 推理的 Attention 计算和 KV Cache 优化:PagedAttention、vAttention 等_paged ...